
排序算法
排序就是把表中的元素进行重新排列的过程,排列后的表中元素满足按关键字递增(减)。本文对排序的一些知识进行整理,算是一篇知识总结类的文章。
排序的分类
根据排序过程中数据元素是否完全在内存中,可以分为两类:内部排序和外部排序。内部排序在排序期间元素全部存放在内存中,而外部排序的排序过程中涉及内外存的数据交换。
内部排序有:插入排序、交换排序、选择排序、归并排序、基数排序。外部排序有:多路归并排序。
排序算法的性质
排序算法的稳定性:对于任何表中的元素a和b(a和b不为同一个元素),若a和b关键字相等,且排序后a和b的相对位置不变。则可以称该排序算法是稳定的。
排序算法的性能指标:时间复杂度(由比较和移动的次数决定)、空间复杂度。
对任意n个关键字进行基于比较的排序,至少要进行ceil(log2(n!))次关键字的两两比较。
由于输入向上向下取整的符号比较麻烦,所以用函数的形式表示:ceil()为向上取整,floor()为向下取整,后面不再赘述
内部排序详解
插入排序
算法思想:每次将一个待排序记录按顺序插入前面已经排好序的子序列,直到子序列长度=原序列长度。
一共有三种插入排序的算法:直接插入排序、折半插入排序和希尔排序。
直接插入排序
直接插入排序原原本本遵守了上述的算法思想。
代码实现
直接插入排序:
void InsertSort(ElemType A[],int n){
int i,j;
for(i=2;i<=n;i++){
if(A[i].key<A[i-1].key){ //当待插入节点关键字小于其前驱节点关键字,才进行插入操作
A[0]=A[i]; //A[0]为哨兵位,每次循环若该元素需要进行插入,会先把该元素放到A[0]
for(j=i-1;A[0].key<A[j].key;j--){ //有的算法书写--j,其实一样的
A[j+1] = A[j];
}
A[j+1]=A[0]; //最后把哨兵中的关键字放在属于它的位置
}
}
}算法性能分析
空间复杂度
空间复杂度为O(1)。仅仅使用了常数个辅助单元。
时间复杂度
最好情况下,排序之前序列已经是有序的了,n个元素涉及n次比较,不需要移动,此时时间复杂度为O(n)。
最坏情况下,表中元素逆序,总的比较次数为n*(n+1)/2,总的移动此时为n*(n+2)/2,此时时间复杂度为O(n^2)。
平均情况下,直接插入算法的时间复杂度为O(n^2)。
稳定性
直接插入排序是稳定的排序算法。
适用性
适用于顺序存储和链式存储的线性表。
折半插入排序
折半插入排序相较于直接插入排序的不同,在于查找的过程使用了折半查找。得益于这一点,在一些特殊的情形该算法效率较高。
代码实现
折半插入排序:
void InsertSort(ElemType A[],int n){
int i,j,low,high,mid; //相较于直接插入,新增加了low,high,mid用于进行折半查找
for(i=0;i<=n,i++){
A[0]=A[i];
low=1;high=i-1;
while(low<=high){ //折半查找的过程
mid=(low+high)/2;
if(A[mid].key<A[0].key) high=mid-1;
else low=mid+1;
}
for(j=i-1;j<high+1;j--)A[j+1]=A[j]; //插入排序的过程
A[high+1]=A[0];
}
}算法性能分析
空间复杂度
空间复杂度为O(1)。仅仅使用了常数个辅助单元。
时间复杂度
元素比较次数减少,但移动次数不改变。时间复杂度仍然为O(n^2)。
稳定性
插入过程和直接插入排序是一样的,所以也是稳定的排序算法。
希尔排序
算法思想:采用分治的方法,将一个序列分解为多个子序列,子序列进行直接插入排序后整个序列再进行一次直接插入排序。
希尔排序的过程:
取步长d1<n,所有距离为d1的倍数的记录放在同一组,这样一共可以分出d1组。在d1各个组中进行直接插入排序。
取第二个步长d2<d1,重复上述过程。
直到dt=1,即所有记录放入同一组,再进行直接插入排序。
关于增量序列的求解,希尔提出下面的方法:d1=n/2,d(i+1)=floor(di/2),并且最后一个增量为1.
代码实现
希尔排序:
void ShellSort(ElemType A[],int n){
int dk,i,j;
for(dk=n/2;dk>=1;dk=dk/2){
for(i=dk+1;i<=n;i++){
if(A[i].key<A[i-dk].key){
A[0]=A[i];
for(j=i-dk;j>0&&A[0].key<A[j].key;j-=dk)A[j+dk]=A[j];
A[j+dk]=A[0];
}
}
}
}算法性能分析
空间复杂度
空间复杂度为O(1)。仅仅使用了常数个辅助单元。
时间复杂度
希尔排序的时间复杂度依赖于增量序列的函数,当n在某个特定范围时时间复杂度约为O(n^1.3),最坏情况下为O(n^2)。平均时间复杂度无法给出。
稳定性
当相同关键字记录被划分到不同的子表时,可能会改变他们的相对次序。因此希尔排序是一种不稳定的排序算法。
适用性
希尔排序仅适用于线性表为顺序存储的情况。
插入排序总结
插入排序有三种:直接插入排序、折半插入排序、希尔排序。
其中前两种稳定,希尔排序不稳定。
时间复杂度方面除了希尔排序无法给出平均时间复杂度外,其他两种均为O(n^2)。
交换排序
交换排序的核心思想是:通过比较两个元素关键字来进行元素位置的对换,进行若干次这种对换后序列呈现有序状态。
常见的交换排序有冒泡排序和快速排序。
冒泡排序
执行冒泡时,当前执行冒泡序列中的元素关键字会按顺序进行两两比较,并根据大小决定是否对换。在执行完一趟冒泡后,最小/最大的元素会排到此序列的最前面。之后不断缩小序列进行冒泡操作(把最前面排好序的那个元素排除掉),直到子序列长度为1或子序列本身有序。最多进行n-1趟冒泡就可以完成排序。
代码实现
冒泡排序:
void BubbleSort(ElemType A[],int n){
int i,j,tmp;
for(i=0;i<n-1;i++){
int flag = false;
for(j=n-1;j>i;j--){
if(A[j]<A[j-1]){ //比较大小并对换操作
tmp=A[j];
A[j]=A[j-1];
A[j-1]=tmp;
flag=true;
}
if(flag==false) return;
//flag==false,说明这一趟没发生对换,即子序列已经是有序的了,直接停止执行
}
}
}算法性能分析
空间复杂度
空间复杂度为O(1)。仅仅使用了常数个辅助单元。
时间复杂度
最好情况下序列初始为有序,比较次数为n-1,交换次数为0,所以时间复杂度为O(n)。
最坏情况下需要进行n-1趟排序,第i趟排序需要进行n-i次比较。此时时间复杂度为O(n^2)。
平均时间复杂度为O(n^2)。
稳定性
比较过程中如果元素关键字相等是不会交换位置的,因此冒泡排序是一种稳定的排序算法。
快速排序
快速排序是考察的比较多的一种算法。其基本思想基于分治法,是对冒泡排序的一种改进。
对于一个排好序的序列,我们任取一个值,可以断定,这个值的前后都是一个有序的子序列。因此如果想要一个乱序的序列变得有序(从小到大排列),我们可以选取一个基准,并保证基准后面的子序列中每个元素都大于基准,基准前面的子序列中每个元素都小于基准。对于这两个子序列本身而言亦是如此。递归执行即可。
在快速排序中,并不产生有序子序列,但每趟排序后会将一个元素放到其最终的位置上(这个元素实际上就是基准)。
代码实现
快速排序:
//划分,将序列初始值选为基准,并对序列进行操作,使基准后面的子序列中每个元素都大于基准,基准前面的子序列中每个元素都小于基准
int Partition(ElemType A[],int low,int high){
ElemType pivot = A[low];
while(low<high){
while(low<high&&A[high]>=pivot) high--;
A[low]=A[high];
while(low<high&&A[low]<=pivot) low++;
A[high]=A[low];
}
A[low]=pivot;
return pivot;
}
void QuickSort(ElemType A[],int low,int high){
if(low<high){
int pivotpos=Partition(A,low,high); //划分两个序列,之后把基准的关键字返回回来
QuickSort(A,low,pivotpos-1); //递归调用
QuickSort(A,pivotpos+1,high);
}
}算法性能分析
空间复杂度
快速排序是递归调用的过程,需要借助递归工作栈来保存每层递归调用的必要信息,容量应该和递归调用的最大深度一致,因此空间复杂度主要就是递归工作栈的深度。平均情况下,栈的深度为O(log2(n)),最坏情况下要进行n-1次递归,此时栈的深度为O(n).
时间复杂度
快速排序的运行时间和划分是否对称有关,所以划分的算法能决定快速排序的时间复杂度。最坏情况下时间复杂度为O(n^2);最好情况下为O(nlog2(n))。
稳定性
快速排序是一种不稳定的排序方式。
选择排序
选择排序的算法思想:每一趟选择排序中,我们需要在执行选择排序的序列中(设趟数为i)选出一个最小/最大的元素作为有序子序列的第i个元素。之后缩短待选择的子序列进行下一次选择排序,直到第n-1趟做完.
选择排序有两种:简单选择排序和堆排序。
简单选择排序
简单选择排序其实就是上面所述算法思想的直观体现。每次从执行简单选择排序的序列中选出最大/最小的元素,如果趟数为i,那么将这个元素和第i个元素交换位置。此时可以发现,从第一个元素到第i个元素已经排好序了,那么从第i+1个元素开始到最后一个元素组成的序列为下一趟简单选择排序的执行序列。
代码实现
简单选择排序:
void SelectSort(ElemType A[],int n){
int tmp = 0;
for(int i=0;i<n-1;i++){ //i<n-1,意味着当待排序子序列只剩一个元素时,我们就可以不用执行了
int minIndex = i;
for(int j=i+1;j<n;j++){ //找出待排序子序列元素关键字最小的位置
if(A[minIndex] > A[j]) minIndex=j;
}
if(minIndex!=i){ //交换元素位置
tmp=A[i];
A[i]=A[minIndex];
A[minIndex]=tmp;
}
}
}算法性能分析
空间复杂度
仅使用常数个辅助单元,空间复杂度为O(1)。
时间复杂度
我们可以知道,简单排序算法交换的次数是很少的,最坏为3(n-1),最好为0;但是元素之前比较的次数和序列的初始状态无关,始终是n(n-1)/2次,所以平均时间复杂度为O(n^2)。
稳定性
简单选择排序是一种不稳定的排序算法。
堆排序
堆排序是一种树形选择排序方法。
学习堆排序,首先要明确堆是什么样的一种数据结构。堆的定义如下:
n个关键字序列L[1...n]称为堆,当且仅当该序列满足:
1.L(i)<=L(2i)且L(i)<=L(2i+1) (小根堆)
2.L(i)>=L(2i)且L(i)>=L(2i+1) (大根堆)
(1<=i<=floor(n/2))用文字描述来说,堆是一棵完全二叉树,并且这棵树满足双亲结点小于(或大于)孩子节点的关系。
实际上,我们可以把数组想象成一棵完全二叉树,并且根据前面的关系来对该数组进行调整,使之成为大根堆或小根堆。在第i趟调整完成后,我们把大根堆(小根堆)的最大(最小)元素和当前堆的最后一个元素对换。之后缩小堆继续调整。重复这个过程,就可以将乱序的数组排好序。这就是堆排序的运作机制。
代码实现
堆排序的灵魂在于建堆,如何把上面的特点呈现成代码的形式也是该算法的难点。
我们可以明确的是,待排序数组可以看成一棵完全二叉树。若数组长度为n,说明该二叉树有n个节点,可以推知双亲节点个数为floor(n/2)个。根据完全二叉树性质,能够成为双亲节点的序列为1~floor(n/2)。这个序列就是i的取值。然后我们需要比较这些双亲节点和其孩子节点的大小并且进行对换。在这里我采取的办法是:如果只有左孩子节点,则直接与双亲节点进行比较;如果有左右孩子节点,则可以用左右孩子节点的较小者和双亲节点比较。
下面代码为了表述方便,我们假定A[0]不存放元素,数组实际长度为n+1。
单个堆的调整代码如下(以小顶堆调整为例):
for(let i=n/2;i>0;i--){
if(2*i+1>n){ //当2i+1>n时,说明最后一个双亲结点没有右子节点,此时仅需要比较左孩子节点和父节点大小,如果父节点更大,则交换位置
if(A[2*i]<A[i]){
A[0]=A[2*i];
A[2*i]=A[i];
A[i]=A[0];
}
}else{ //这个else其实仅有一种可能,那就是2i+1=n
if(A[2*i]>A[2*i+1]){ //比较左右孩子节点并使2*i为最小者
A[0]=A[2*i];
A[2*i]=A[2*i+1];
A[2*i]=A[0];
}
if(A[2*i]<A[i]){ //比较父节点与2*i孩子节点的较小者,如果父节点更大,则交换位置
A[0]=A[i];
A[i]=A[2*i];
A[2*i]=A[0];
}
}
}因为我们进行堆排序,堆的大小是可变的,需要对上面代码进行改造:
void createMinHeap(ElemType A[],int len){
for(let i=len/2;i>0;i--){
if(2*i+1>len){ //当2i+1>len时,说明最后一个双亲结点没有右子节点,此时仅需要比较左孩子节点和父节点大小,如果父节点更大,则交换位置
if(A[2*i]<A[i]){
A[0]=A[2*i];
A[2*i]=A[i];
A[i]=A[0];
}
} else{ //这个else其实仅有一种可能,那就是2i+1=len
if(A[2*i]>A[2*i+1]){ //比较左右孩子节点并使2*i为最小者
A[0]=A[2*i];
A[2*i]=A[2*i+1];
A[2*i]=A[0];
}
if(A[2*i]<A[i]){ //比较父节点与2*i孩子节点的较小者,如果父节点更大,则交换位置
A[0]=A[i];
A[i]=A[2*i];
A[2*i]=A[0];
}
}
}
}然后堆排序的代码无非就是建堆和调换这两个过程:
void heapSort(ElemType A[],int n){
int tmp;
for(int i=n;i>1;i--){
createMinHeap(A,i);
tmp=A[i];
A[i]=A[1];
A[1]=A[tmp];
}
}算法性能分析
空间复杂度
使用常数个辅助单元,空间复杂度为O(1)。
时间复杂度
在最好、最坏、平均情况下时间复杂度为O(nlog2(n))。
稳定性
堆排序算法是一种不稳定的排序算法。
归并排序
归并排序的基本思想是将两个或两个以上的有序表组合成一个新的有序表。这是一种基于分治的排序算法。
根据其过程可以很轻松地写出递归调用的代码,但是我们需要思考,如何将两个有序序列合并为一个有序序列呢?
归并排序提供的方法是这样的:首先用一个辅助数组B将整个数组A备份过去。然后对于B中的两个有序子序列,使用双指针法,比较两个指针指向元素的最大者(最小者)并放入A对应位置,对应序列的指针向前移动。按照这样的过程一直执行,直到访问完其中一个序列的元素为止。最后把没访问完的序列的剩余部分直接复制到A中。
代码实现
ElemType *B=(ElemType*)malloc((n+1)*sizeof(ElemType)); //申请辅助数组内存空间
void Merge(ElemType A[],int low,int mid,int high){
for(int k=low;k<=high;k++) B[k]=A[k]; //将执行归并的序列复制到辅助数组
for(int i=low,j=mid+1,k=i;i<=mid&&j<=high;k++){
if(B[i]<=B[j]) A[k]=B[i++];
else A[k]=B[j++];
}
//最后把没访问完的序列的剩余部分直接复制到A中
while(i<=mid) A[k++]=B[i++];
while(j<=high) A[k++]=B[j++];
}
void MergeSort(ElemType A[],int low,int high){
if(low<high){
int mid=(low+high)/2;
MergeSort(A,low,mid); //对左序列递归执行归并排序使之有序
MergeSort(A,mid+1,high); //归并右序列递归执行归并排序使之有序
Merge(A,low,mid,high); //归并左右序列使整体有序
}
}算法性能分析
空间复杂度
申请辅助空间有n+1个,所以空间复杂度为O(n)。
时间复杂度
每趟归并时间复杂度为O(n),执行ceil(log2(n))趟,所以算法时间复杂度为O(nlog2(n))。
稳定性
归并排序是一种不稳定的排序算法。
基数排序
基数排序的排序依据是关键字各位的大小。鉴于其公式表述极其晦涩难懂,下面是从菜鸟教程找的动图,结合这个动图来分析基数排序的整个过程(以最低位优先为例,最高位优先同理):

我们初始创建0~9十个队列。初始序列根据个位数进行入队操作,全部入队完毕后0~9序列按顺序全部出队,这个按顺序输出的就是第一趟排序的结果。接着执行第二趟,第二趟根据十位数进行入队操作(没有十位数则加入到队列0),之后再按顺序出队。可以发现这样以后整个序列就排序完成了。
掌握其思想写出代码不算很难,就是麻烦。因为要写获取关键字各位数的方法,还要涉及队列入队出队操作。总之很麻烦所以懒得代码实现了。具体实现见1.10 基数排序 | 菜鸟教程 (runoob.com)。
算法性能分析
空间复杂度
使用r个辅助队列(可能不是十进制数,所以不一定为10个),空间复杂度为O(r)。
时间复杂度
基数排序分为分配和收集两个过程,分配就是各元素挑选队列入队的过程,收集就是各序列按顺序出队(各个队列中的节点依次首尾相接)。分配过程消耗时间O(n),收集消耗时间O(r),共经历d趟,所以总的时间复杂度为O(d(n+r))。
稳定性
基数排序是稳定的排序算法。
总结
前面的算法解析还算比较详尽,下面就对各排序算法的性质以表格的形式进行汇总:
| 算法种类 | 时间复杂度(最好) | 时间复杂度(最差) | 时间复杂度(平均) | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 直接插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 简单选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 希尔排序 | × | × | × | O(1) | 不稳定 |
| 快速排序 | O(nlog2(n)) | O(n^2) | O(nlog2(n)) | O(nlog2(n)) | 不稳定 |
| 堆排序 | O(nlog2(n)) | O(nlog2(n)) | O(nlog2(n)) | O(1) | 不稳定 |
| 2路-归并排序 | O(nlog2(n)) | O(nlog2(n)) | O(nlog2(n)) | O(n) | 稳定 |
| 基数排序 | O(d(n+r)) | O(d(n+r)) | O(d(n+r)) | O(r) | 稳定 |
光了解算法本身不去使用,学习算法就没有意义了。因此除了了解这些算法的思想以及性质之外,还需要根据算法的性质来明确使用的场景。下面是对排序算法选择的总结:
1.对于基本有序的关键字,使用直接插入或冒泡往往更好(时间复杂度为O(n))。
2.对于关键字较少的(n<=50),可以选用直接插入或者简单选择排序。相比之下简单选择排序移动次数更少,所以最优为简单选择排序。
3.对于关键字较多的(n>50),可以选用快速排序、堆排序或归并排序。快速排序在待排序关键字随机分布的情况下最优;堆排序相比于快速排序使用更少的内存空间,且不会出现最坏情况。如果需要稳定的排序方式,则选用归并排序。
4.如果n很大,记录的关键字位数少且可以分解时,采用基数排序较好。
5.信息量大的情况下,链式存储优于顺序存储。外部排序详解
外部排序涉及内存和外存之间的数据交换,数据比较大,通常使用归并排序。
外部排序的过程
排序的过程大致是:
1.根据内存缓冲区大小将外存含n条记录的文件划分成h个段。依次读入内存进行内部排序并将排序得到的和有序段写回外存。(这个过程完成了初始归并段的构造)。
2.对这些归并段进行归并排序,直到得到整个有序文件为止。(将归并段读入输入缓冲区,进行内部归并。当输出缓冲区满时将输出缓冲区的内容写回内存后清空输出缓冲区;若某个输入缓冲区数据都被读完了空出来了,就将对应的归并段的剩余数据按顺序补进去,继续参加归并。采用k路归并时需要k个输入缓冲区和1个输出缓冲区)对于这个过程所耗费的时间,有如下公式:
外部排序总时间 = 内部排序所需时间 + 外存信息读写时间 + 内部归并所需时间即:
Tes = rTis + dTio + S(n-1)Tmgr为初始归并段的个数,Tis是对每个初始归并段进行内部排序的时间,Tio是每个块的存储时间,d是访问外存块的次数,S是执行归并的趟数,n是每趟参加2路归并的记录个数,Tmg是每做一次内部归并时,取得一个关键字最小记录的时间。
根据以上的关系,结合实际情况可以得知,我们要想减少外部排序耗费的时间,就要着手于减少外存读写的次数。
对于读写磁盘次数,有:
读写磁盘次数 = 文件总块数*2 + (文件总块数*2)*内部归并趟数其中,前面的文件总块数*2是指构造归并段的时候涉及的磁盘读写,而后面的 (文件总块数*2)*内部归并趟数则涉及内部归并时所进行的磁盘读写。所以减少内部归并趟数可以帮助我们减少读写磁盘次数。增大归并路数可以减少归并趟数,进而减少总的I/O次数。
对r个初始归并段做m路平衡归并,归并树可以用严格m叉树表示。第一趟将r个初始归并段归并为ceil(r/m)记为l,以后每趟归并将l个归并段归并为ceil(l/m)个归并段,直到形成一个大的归并段为止。归并趟数 = 树的高度 = ceil(logm(r))。多路平衡归并和败者树
前面说到增大归并路数可以减少归并趟数进而减少总的I/O次数,但是增大归并路数会增加内部归并的时间。为了解决这个问题,引入败者树对内部归并进行了优化。
败者树的概念比较简单,这里去百度百科偷了张图:
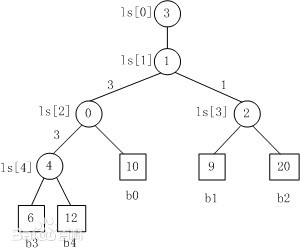
上面就是一棵败者树,可以看到叶子节点为待比较的数据,b后面的数字是关键字所在段号。第一趟比较中,将叶子的兄弟节点进行两两比较,并将败者所在的段标记存入父节点,胜者则与兄弟(兄弟的胜者)再进行比较。到最后可以看到最顶上节点存放的是最终的胜者段标记。之后输入胜者,在胜者所在的叶子节点处补上该段的下一个关键字。从第二趟开始就不需要全部重新决胜负了,只需要从新数据出发进行比较就可以了。
在引入败者树后,归并路数和内部归并时间无关了。此时只要空间允许,增大归并路数将有效减少归并数的高度(归并趟数),从而减少总的I/O次数。(增加归并路数则需要增加输入缓冲区的个数,如果空间有限,输入缓冲区容量变小,这时候虽然减少了归并趟数,读写外存数量仍会增加)
置换-选择排序
在前面我们有提到:
对r个初始归并段做m路平衡归并,归并树可以用严格m叉树表示。第一趟将r个初始归并段归并为ceil(r/m)记为l,以后每趟归并将l个归并段归并为ceil(l/m)个归并段,直到形成一个大的归并段为止。归并趟数 = 树的高度 = ceil(logm(r))。
可以知道初始归并段的个数也是影响归并趟数的因素,只要减小r,归并趟数就下去了,总的I/O次数也会减少。置换-选择排序算法所完成的事情正是在初始化归并段时让r尽可能地少。
关于置换-选择排序过程的描述,比较抽象。下面简单用表格演示一下:
初始条件:待排序文件FI,初始归并段文件为FO,内存工作区WA可容纳w条记录且w=3。
| 输出文件FO | 工作区WA | 输入文件FI | MINMAX |
|---|---|---|---|
| - | - | 1,2,3,5,9,12,25,11,7,4,8 | - |
| - | 1,2,3 | 5,9,12,25,11,7,4,8 | - |
| 1 | 5,2,3 | 9,12,25,11,7,4,8 | 1 |
| 1,2 | 5,9,3 | 12,25,11,7,4,8 | 2 |
| 1,2,3 | 5,9,12 | 25,11,7,4,8 | 3 |
| 1,2,3,5 | 25,9,12 | 11,7,4,8 | 5 |
| 1,2,3,5,9 | 25,11,12 | 7,4,8 | 9 |
| 1,2,3,5,9,11 | 25,7,12 | 4,8 | 11 |
| 1,2,3,5,9,11,12 | 25,7,4 | 8 | 12 |
| 1,2,3,5,9,11,12,25 | 8,7,4 | - | 25 |
| 4 | 8,7,_ | - | 4 |
| 4,7 | _,8,_ | - | 7 |
| 4,7,8 | - | - | 8 |
初始化归并段结果分别为1,2,3,5,9,11,12,25和4,7,8。上面的算法中的MINMAX的选取需要利用败者树实现。
详细的解析以及代码实现可以见置换选择排序算法 (biancheng.net)。
最佳归并树
哈夫曼树
在介绍最佳归并树之前,先回顾一下哈夫曼树的知识。
当用 n 个结点(都做叶子结点且都有各自的权值)试图构建一棵树时,如果构建的这棵树的带权路径长度最小,称这棵树为“最优二叉树”,有时也叫“赫夫曼树”或者“哈夫曼树”。
哈夫曼树相关的一些名词:
路径:在一棵树中,一个结点到另一个结点之间的通路,称为路径。图 1 中,从根结点到结点 a 之间的通路就是一条路径。
路径长度:在一条路径中,每经过一个结点,路径长度都要加 1 。例如在一棵树中,规定根结点所在层数为1层,那么从根结点到第 i 层结点的路径长度为 i - 1 。图 1 中从根结点到结点 c 的路径长度为 3。
结点的权:给每一个结点赋予一个新的数值,被称为这个结点的权。例如,图 1 中结点 a 的权为 7,结点 b 的权为 5。
结点的带权路径长度:指的是从根结点到该结点之间的路径长度与该结点的权的乘积。例如,图 1 中结点 b 的带权路径长度为 2 * 5 = 10 。
树的带权路径长度为树中所有叶子结点的带权路径长度之和。通常记作 “WPL” ,WPL = 哈夫曼树中所有非叶子结点的权值之和构建哈夫曼树的过程:
在 n 个权值中选出两个最小的权值,对应的两个结点组成一个新的二叉树,且新二叉树的根结点的权值为左右孩子权值的和;
在原有的 n 个权值中删除那两个最小的权值,同时将新的权值加入到 n–2 个权值的行列中,以此类推;
重复 1 和 2 ,直到所以的结点构建成了一棵二叉树为止,这棵树就是哈夫曼树。比较详尽的哈夫曼树介绍以及代码实现见哈夫曼树(赫夫曼树、最优树)详解 (biancheng.net)。
最佳归并树
在经过置换-选择排序之后,我们得到若干长度不等的初始归并段。这些归并段可以组织成若干棵归并树,其中I/O次数最少的就是最佳归并树。
对于一棵归并树而言,其WPL和在归并过程中总的I/O次数有着如下的关系:
在归并过程中总的I/O次数 = 2*WPL因此,我们可以知道,当WPL最小的时候,总的I/O次数最小。因此可以使用哈夫曼树构建的方式来构建最佳归并树。
当然,这里有个限制,最佳归并树必须是严格的m叉树。但是如果段数对不上的情况要怎么解决呢?这里需要引入长度为0的虚段进行补足。
关于补足虚段的数量,下面进行推导:
设有Nk个初始归并段,有Nm个度为m的节点
有:Nk = (m-1)*Nm + 1
=> Nm = (Nk-1)/(m-1)
可以知道,在严格m叉树情况下,Nm应该为整数,所以有(Nk-1)%(m-1)=0。
如果(Nk-1)%(m-1)≠0,则需要补充虚段k个,满足k=(Nk-1)%(m-1)。